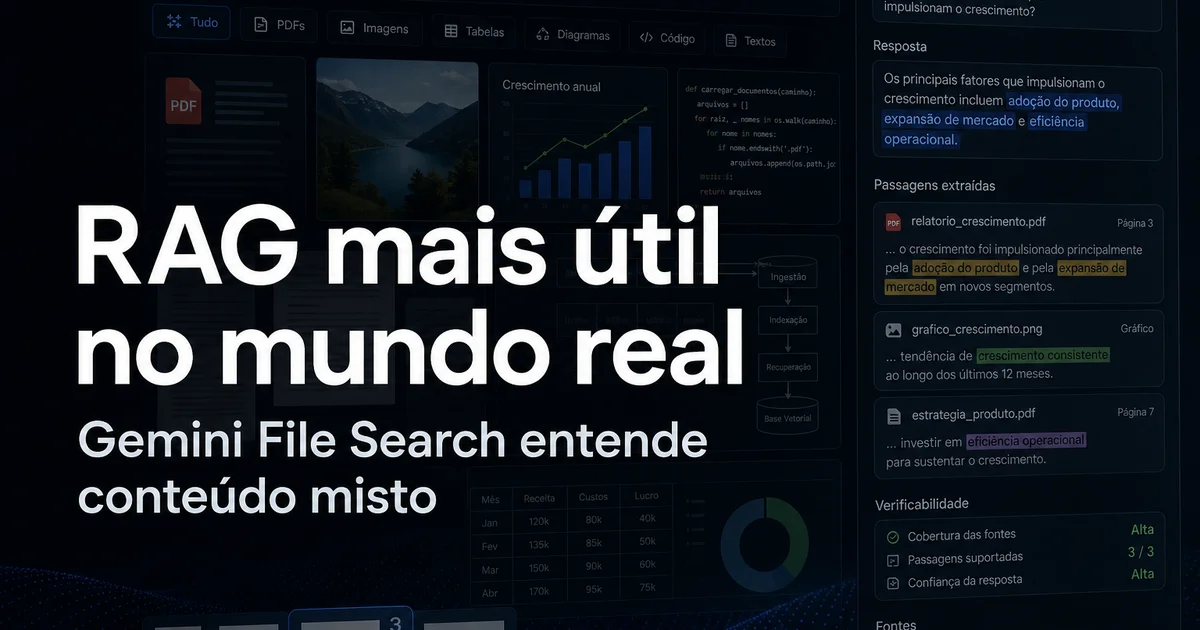
O RAG sempre prometeu muito. Na prática, boa parte do trabalho virou engenharia de contenção de danos. Extrair texto de PDF, tratar imagem separada, preservar contexto, montar índice, torcer para a resposta citar a fonte certa. Agora o Gemini API File Search deu um passo que interessa menos para demo e mais para operação: ficou multimodal, ganhou metadata customizada e passou a oferecer citações por página.
Não é uma revolução mágica. Mas é uma melhora objetiva no ponto em que muitos times travam quando tentam usar busca sobre documentos reais, cheios de imagem, tabela, layout ruim e contexto espalhado.
o que mudou de fato
O Google anunciou três atualizações principais no File Search do Gemini API.
A primeira é o suporte multimodal. Na prática, a busca passa a processar imagem e texto juntos no mesmo fluxo. Isso importa porque muitos documentos úteis não são só texto corrido. São PDFs com gráfico, captura de tela, diagrama, formulário escaneado, slide, manual técnico e relatório com elementos visuais que carregam parte do significado.
A segunda é metadata customizada. Agora dá para anexar rótulos em chave-valor aos arquivos e usar isso como filtro na recuperação. Parece detalhe, mas reduz ruído de forma brutal em base interna grande. Você deixa de perguntar “o que é relevante?” só para o embedding e passa a impor contexto operacional: área, região, produto, versão, classificação, data, idioma ou status regulatório.
A terceira é a citação por página. Esse ponto é talvez o mais importante para qualquer caso sério. O sistema consegue apontar a página de onde veio o trecho recuperado. Em RAG, isso melhora grounding, transparência e auditoria. Em português claro: fica mais fácil verificar se a resposta está ancorada em algo real.
por que isso pesa mais no mundo real do que em benchmark
Quem trabalha com base documental interna sabe onde a teoria costuma quebrar. O problema raramente é só “buscar um texto parecido”. O problema é buscar o trecho certo dentro de um documento imperfeito, com sinais espalhados entre texto, imagem e layout.
Um manual de suporte pode ter uma captura de tela que resolve mais do que o parágrafo ao lado. Um PDF regulatório pode trazer a regra principal em uma tabela. Um playbook interno pode depender da distinção entre versões quase idênticas. Quando o pipeline trata tudo como texto achatado, a perda de contexto vira erro operacional.
O File Search já fazia o básico esperado: importar arquivos, quebrar em chunks, indexar os dados e recuperar trechos relevantes para RAG. O avanço agora é que esse fluxo fica menos cego para conteúdo misto e mais governável na etapa de recuperação.
Isso não elimina a necessidade de arquitetura. Mas reduz a quantidade de remendo manual para fazer a busca parecer minimamente confiável.
menos pipeline artesanal
Boa parte dos times que implementou RAG em produção acabou montando pipeline paralelo para cada tipo de arquivo. OCR de um lado, parser de PDF de outro, extração de imagem em outra etapa, normalização, tagging externo, reindexação e, no fim, um monte de cola entre serviços.
Esse tipo de pipeline custa tempo, gera manutenção e falha em silêncio. Quando falha, quase sempre sobra para o usuário final na forma de resposta confiante e errada.
Quando a camada de busca já entende conteúdo multimodal, o ganho não é só técnico. É de operação. Menos componentes para orquestrar. Menos perda de contexto na conversão. Menos chance de quebrar na borda. E mais velocidade para publicar um caso de uso que funcione sem parecer protótipo eterno.
Não quer dizer que o problema acabou. PDF ruim continua existindo. Documento escaneado continua sendo documento escaneado. Mas o ponto muda: em vez de gastar energia só para deixar os dados “buscáveis”, o time pode gastar energia no que interessa, que é política de acesso, qualidade da base, avaliação e fluxo de decisão.
suporte, compliance e base interna são os casos óbvios
Esse tipo de melhoria faz mais sentido em três frentes.
Em suporte, porque a base raramente é limpa. Há artigo interno, print de sistema, changelog, FAQ e documentação técnica com versões diferentes. A metadata ajuda a filtrar por produto, release ou canal. A multimodalidade ajuda quando a resposta depende de interface ou diagrama. E a citação por página ajuda o analista a confiar no que foi recuperado.
Em compliance, porque resposta sem trilha de fonte é quase inútil. Não basta dizer “a política prevê isso”. É preciso mostrar de onde saiu, em qual documento e em qual página. Citação por página não resolve governança inteira, mas já muda a conversa entre automação e auditoria.
Em base interna, porque o ruído é o inimigo principal. Empresas acumulam documentos redundantes, antigos, conflitantes e mal rotulados. A metadata customizada funciona como freio. Em vez de jogar toda a entropia no vetor e esperar milagre, você filtra antes: apenas documentos de uma área, de um país, de uma versão válida, de um período específico.
É o tipo de ajuste que parece banal para quem olha de fora, mas muda muito a taxa de acerto na prática.
o ponto central é verificabilidade
O hype em torno de RAG sempre vendeu “redução de alucinação”. O problema é que isso virou slogan frouxo. Sem fonte clara, sem recorte preciso e sem controle de contexto, o sistema até pode responder melhor que um modelo puro, mas continua difícil de auditar.
É aí que a citação por página pesa. Ela não é só um enfeite de UX. Ela aproxima o produto de uma rotina de trabalho onde alguém precisa conferir, justificar ou aprovar uma resposta. Em áreas reguladas, isso é requisito, não luxo. Em suporte interno, é o que impede o bot de virar mais um canal que ninguém leva a sério.
RAG útil não é o que responde bonito. É o que permite checagem rápida.
o que ainda não convém romantizar
Também vale baixar a temperatura. Multimodalidade na busca não significa compreensão perfeita de qualquer documento bagunçado. Metadata boa depende de disciplina de catalogação. E citação por página é ótima, mas não substitui avaliação contínua de relevância, cobertura e conflito entre fontes.
Além disso, nenhum sistema de recuperação resolve sozinho o problema de documento desatualizado. Se a base está ruim, a resposta será elegantemente ruim.
Então o ganho aqui não é “agora RAG funciona”. O ganho é mais específico e mais honesto: ficou mais fácil montar um RAG verificável, com menos trabalho manual, para cenários em que arquivo de verdade importa mais do que benchmark bonito.
conclusão
O avanço do Gemini File Search não está em parecer futurista. Está em atacar três dores concretas ao mesmo tempo: entender conteúdo misto, filtrar melhor o universo de busca e mostrar com mais precisão de onde veio a resposta.
Isso aproxima o RAG de um uso menos teatral e mais operacional. Suporte, compliance e base interna tendem a sentir esse impacto primeiro. Não porque sejam os casos mais chamativos, mas porque são os que mais sofrem com documento feio, contexto confuso e exigência de rastreabilidade.
No fim, a melhor notícia talvez seja esta: o valor aqui não está em prometer inteligência geral sobre arquivos. Está em reduzir atrito onde antes havia pipeline demais e verificabilidade de menos.
fontes
- Google Blog: Expanded Gemini API File Search for multimodal RAG
- Gemini API Docs: File Search

